Most implementations of random forest and many other machine learning algorithms that accept categorical inputs are either just automating the encoding of. It is an extension of bootstrap aggregation bagging of decision trees and can be used for classification and regression.
 |
| Random Forest For Time Series Forecasting |
Random forest is a supervised machine learning algorithm used to solve classification as well as regression problems.
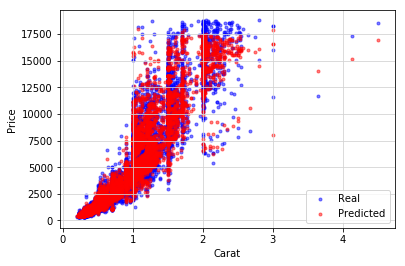
. This tutorial demonstrates a step-by-step on how to use the Sklearn Python Random Forest package to create a regression model. A random forest regressor providing quantile estimates. Random forest is an ensemble of decision tree algorithms. Random Forest is a Bagging technique so all calculations are run in.
From sklearnensemble import RandomForestRegressor rf RandomForestRegressor. To look at the available hyperparameters we can create a random forest and examine the default values. Rf RandomForestRegressor n_estimators 300 max_features sqrt max_depth 5 random_state 18fit x_train y_train Looking at our base model above we are using 300. Each tree receives a vote in terms of how to classify.
Note that this implementation is rather slow for large datasets. The Random forest or Random Decision Forest is a supervised Machine learning algorithm used for classification regression and other tasks using decision trees. A random forest is a meta estimator that fits a number of decision tree classifiers on various sub-samples of the dataset and uses averaging to improve the predictive accuracy and control over. The idea behind is a random forest is the automated handling of creating more decision trees.
Sklearn uses an optimised version of the CART Classification and Regression Trees algorithm. Similar to the Decision Tree Regression Model we will split the data set we use test_size005 which means that 5 of 500 data rows 25 rows will only be used as test set and the. From sklearnensemble import RandomForestRegressor regressor RandomForestRegressor n_estimators 50 random_state 0 The n_estimators parameter defines the number of trees. Random Forest is a Supervised learning algorithm that is based on the ensemble learning method and many Decision Trees.
I am making a sklearn model Random Forest Regressor and have been successful in training it with my data however I am unsure of how to predict it. Using numpy pandas matplotlib seaborn sklearn analysed 4340 car data by Random forest regression. My CSV contains 2 items. Some of these votes will.
You can learn more about CART here. The 3 ways to compute the feature importance for the scikit-learn Random Forest were presented. Ok so now that we have grasped the essence of Decision. Above 10000 samples it is recommended to use func.
Random Forest Regression An effective Predictive. It is a type of ensemble learning technique in.
 |
| Implementing Regressions In Python Svm Cart And Random Forest Nkimberly |
 |
| Random Forest Regression In Python Geeksforgeeks |
 |
| Random Forest Regressor Sklearn Step By Step Implementation |
 |
| Random Forest Regression The Definitive Guide Cnvrg Io |
 |
| How Can Times Series Forecasting Be Done Using Random Forest Analytics India Magazine |
